hadoop组件之hbase环境搭建
本文共 2900 字,大约阅读时间需要 9 分钟。
文章目录
一.安装HBase之前,需要具备如下三个前置条件
-
1.HBASE的运行需要JDK
-
2.HBase的底层存储依赖于HDFS,需要安装hadoop环境
-
3.HBase依赖于ZooKeeper来做分布式协调工作,所以需要安装Zookeeper的环境,本文使用自己搭建的环境不使用hbase内置
二.安装HBase与配置环境变量
- 1.下载安装包:
- 2.拖入opt目录并解压安装:
tar -zxvf hbase-1.2.0-cdh5.14.2.tar.gz - 3.改名:
mv hbase-1.2.0-cdh5.14.2/ hbase - 4.删除安装包:
rm -rf hbase-1.2.0-cdh5.14.2.tar.gz - 5.配置环境变量:
vi /etc/profile,加入如下内容:
export HBASE_HOME=/opt/hbaseexport PATH=$PATH:$HBASE_HOME/bin
- 6.执行:
source /etc/profile使其生效
三.HBase配置(主要掌握完全分布式)
1.单机模式
- 解压后即可在单机模式下运行.此模式只需要在hbase-stie.xml中指定HBase的文件存储目录即可
- 1)进入配置文件目录:
cd /opt/hbase/conf/ - 2)修改hbase-stie.xml文件:
vi hbase-site.xml - 3)在configuration标签内插入如下内容:
hbase.rootdir file:///opt/hbase/hbaseTmp
- 4)启动命令:
start-hbase.sh,使用jps查看仅运行HMaster:
- 5)关闭命令:
stop-hbase.sh
2.伪分布模式
- HBase只在单节点上运行,和单机模式一样,但该节点会运行HMaster,HRegionServer,HQuorumPeer共三个进程
- 1)进入配置文件目录:
cd /opt/hbase/conf/ - 2)修改hbase-stie.xml文件:
vi hbase-site.xml - 3)在configuration标签内插入如下内容:
hbase.rootdir hdfs://hadoop112:9000/hbase hbase.cluster.distributed true
- 4)在hbase-env.sh文件中指定jdk路径:
vi hbase-env.sh, 添加jdk路径:
export JAVA_HOME=/opt/jdk1.8.0_221
- 由于此时HBase使用的为hdfs所以必须先启动hdfs,然后启动HBase;停止时先停止HBase,然后停止hdfs
- 5)启动hdfs:
start-dfs.sh,启动hbase:start-hbase.sh - 6)关闭hbase:
stop-hbase.sh, 关闭hdfs:stop-dfs.sh
3.完全分布模式(!!!重要)
前提:所有机器的时钟误差不大于30秒,配置时钟同步请看如下链接:
- 进入配置目录:
cd /opt/hbase/conf/ - 1)配置hbase-site.xml文件:
vi hbase-site.xml,在configuration标签内插入如下内容:
hbase.rootdir hdfs://hadoop110:9000/hbase hbase.cluster.distributed true hbase.master hadoop110:6000 hbase.zookeeper.quorum hadoop110,hadoop111,hadoop112
- 2)配置hbase-env.sh文件:
vi hbase-env.sh,添加相关环境变量:
export JAVA_HOME=/opt/jdk1.8.0_221export HBASE_HOME=/opt/hbaseexport HADOOP_HOME=/opt/hadoop-2.6.0-cdh5.14.2#表示内置zookeeper不开启(手动配置了zookeeper集群)export HBASE_MANAGES_ZK=false
- 3)配置regionservers文件:
vi regionservers - 该文件列出了所有HRegionServer节点(一般不包含HMaster的机器),如下:
hadoop111hadoop112
- 4)将hbase目录和环境变量文件整个复制到其他机器:如下
scp -r /opt/hbase root@hadoop111:/opt/hbasescp /etc/profile root@hadoop111:/etc/profile- 其他机器记得
source /etc/profile使配置生效 - 5)启动:首先在hadoop主机器启动hdfs:
start-dfs.sh,然后启动所有机器的zookeeper:zkServer.sh start,最后在主机器启动HBase:start-hbase.sh - 6)验证,通过
hbase shell命令进入,然后使用命令list查看所有表,初始状态应该是0,如下图(输入exit退出hbase shell):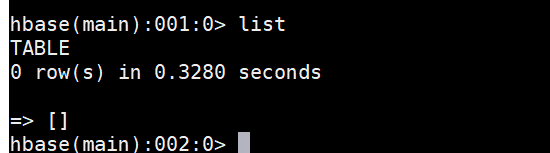
- 注:
hbase shell命令每台机器都需要进去看看是否能成功 - 还可以通过HMaster节点的60010端口查看HBase运行状态: http://192.168.56.110:60010,如下图:

- 7.关闭hbase:
stop-hbase.sh
转载地址:http://xdjxi.baihongyu.com/
你可能感兴趣的文章
Ubuntu10.10 CAJView安装 读取nh\kdh\caj文件 成功
查看>>
kermit的安装和配置
查看>>
vim 配置
查看>>
openocd zylin
查看>>
进程创建时文件系统处理
查看>>
进程创建时信号处理函数处理
查看>>
进程创建时信号处理
查看>>
进程创建时内存描述符处理
查看>>
进程创建时命名空间处理
查看>>
进程创建时IO处理
查看>>
进程创建时线程栈处理
查看>>
进程创建时pid分配
查看>>
进程创建时安全计算处理
查看>>
进程创建时cgroup处理
查看>>
idle进程创建
查看>>
内核线程创建
查看>>
linux elf tool readelf
查看>>
linux tool objdump
查看>>
linux tool nm
查看>>
字节对齐
查看>>